








 English
English
 Français
Français
 Deutsch
Deutsch
 Italiano
Italiano
 Español
Español

Non-fiction
Technologie
 11 min
11 min

Non-fiction
Technologie
11 min




𝗟𝗲 𝗣𝗿𝗲𝗺𝗶𝗲𝗿 𝗛𝗼𝗺𝗺𝗲 𝗮̀ 𝗮𝘃𝗼𝗶𝗿 𝗺𝗮𝗿𝗰𝗵𝗲́ 𝘀𝘂𝗿 𝗹𝗮 𝗡𝗼𝘁𝗶𝗰𝗲 𝗣𝗮𝗻𝗼𝗱𝘆𝘀𝘀𝗲𝘆



 Contribuer
Contribuer
Directive Content-Signal
L’idée sympa de Cloudflare
Alexandre m’a fait écrire des recommandations CSS. Gabriel m’a vendu Infomaniak. Quelques verres de Grignan-les-Adhémar aidant, je me suis mis à écrire deux ou trois lignes de code. Ça, c’est pour votre anecdote au coin du feu dans 20 ans.
Justement, en parlant de 20 ans, le paysage du web a quand même bien changé depuis le début des années 2000. Et on n’écrit plus les permissions d’accès à nos sites internet de la même façon. Le modèle vertueux selon lesquels les moteurs de recherche renvoyaient vers les sites qui leur permettaient d’explorer leurs contenus, c’est du passé.
L’IA est arrivée avec ses gros sabots et une culture du pillage qui balaye d’un revers de main le modèle économique sur lequel le web s’est construit.
Si vous suivez activement l’actualité de Panodyssey et que vous utilisez la Notice, vous avez certainement entendu parler d’ opt-out . Derrière ce gros-mot, se cache le signalement de votre refus de “fouille de texte et de données” par les agents IA. C’est porté par le protocole TDMRep (Text and Data Mining Reservation Protocol) et par la directive européenne 2019/790 concernant le droit d'auteur et les droits voisins.
Les anciens codeurs comme moi ont un réflexe quand on parle de robots. Le fameux fichier robots.txt placé à la racine du répertorie de votre site. Ben oui, les fichiers d’un site, c’est comme les fichiers de votre disque dur : ils sont rangés dans des répertoires.
La liste de Schindler
Votre robots.txt peut faire trois lignes comme des centaines de lignes en fonction de l’usage plus ou moins avancé que vous en faites. Les plus basiques servent à empêcher l’accès à certains dossiers. Et parfois, on peut faire des bêtises impactant gravement le SEO en privant les moteurs de recherche de comprendre notre UX. Les plus avancés permettent d’orienter et d’optimiser le trafic de votre site.
Ce n’est pas la solution la plus optimale, mais c’est la plus facile à écrire et à mettre en place. Et surtout, sa lecture est obligatoire pour les robots qui visitent votre site. Ce qui à l’horizon 2029 pourrait être supérieur au trafic humain.
Puisque qu’il permet de définir les droits pour chaque robot, le premier réflexe est d’y coller une liste d’agents qui ne sont pas autorisés. Il suffit de faire ça par exemple :
User-agent: MistralAI-User
Disallow: /
On peut en mettre plusieurs à la suite :
User-agent: MistralAI-User
User-agent: ChatGPT Agent
User-agent: ChatGPT-User
User-agent: anthropic-ai
Disallow: /
On commence comme ça et on fini par avoir une liste aussi longue que celle de monsieur Oskar Schindler, un industriel allemand du siècle dernier, connu pour sa fameuse liste qui a sauvé la vie à de nombreuses personnes. En tout cas, la liste contenue par le fichier robots.txt du journal Le Monde en prend la voie. Et ce n’est pas la plus longue que j’ai trouvé. (Oui, j’ai lu le robots.txt du Monde, et alors ?)
Au rythme où les choses évoluent, il faudrait presque employer un pigiste à temps plein pour mettre à jour ce fichier robots.txt . Or, ce n’est pas vraiment l’idée d’origine de ce gentil petit fichier. C’est là que Cloudflare entre en scène avec une proposition sincèrement intéressante : la Content Signal Policy lancée fin septembre 2025.
Une Directive pour les lier tous.
Cloudflare propose une idée simple et cohérente : l’ajout d’une directive au fichier robots.txt pour contrôler ce que les IA peuvent faire de vos contenus. Et quand une idée aussi simple est promue par l’une des entreprise les plus puissantes du web, elle est en bonne voie pour faire école.
D’ailleurs, Cloudflare est littéralement un mastodonte du web dont il contrôle 20% du traffic mondial. Sa solution de CDN (Content Delivery Network) représente plus de 80% de parts de marché.
Par ailleurs, l’entreprise a automatiquement déployé sa Content Signal Policy sur 3,8 millions de domaines via son service de robots.txt géré.
Et même si vous n’êtes pas client, Cloudflare vous propose de la générer gratuitement sur le site qui lui est dédié : https://contentsignals.org/
Voyons à quoi ça ressemble et quels en sont les avantages.
Alors à quoi ressemble le fichier robots.txt de demain ?
D’abord une déclaration de condition d’accès assortie d’une clause juridique contraignante qui fait directement référence à la Directive européenne 2019/790 sur le droit d’auteur dans le marché unique numérique .
Ensuite viennent les règles Content-Signal qui définissent trois préférences :
- ai-train définit une préférence concernant l’entraînement des modèles d’IA.
- ai-train=yes indique que l’entraînement est autorisé sur les contenus du site.
- ai-train=no indique au contraire qu’il est interdit d’utiliser les contenus concernés pour entraîner une IA.
- ai-input définit une préférence concernant l’utilisation par les IA de vos contenus pour enrichir des réponses (AI Overviews, recherche en temps réel, etc.).
- ai-input=yes autorise l’usage des contenus pour enrichir les réponses des IA.
- ai-input=no indique qu’il est interdit d’utiliser les contenus pour enrichir les réponses des IA.
- search définit une préférence concernant la construction d’un index de recherche comme celui de Google ou de Bing sans utilisation de l’IA (AI Overviews et équivalent). En clair, il s’agit de la recherche traditionnelle.
- search=yes permet d’utiliser les contenus pour construire un index de recherche.
- search=no interdit cet usage.
Et là, ça devient sympa ! On peut adresser la même directive à tous les agents, d’un coup. Evidemment on peut toujours viser un agent spécifique et protéger des pages et des répertoires particuliers comme on le faisait avant.

Photo: Anton Maksimov
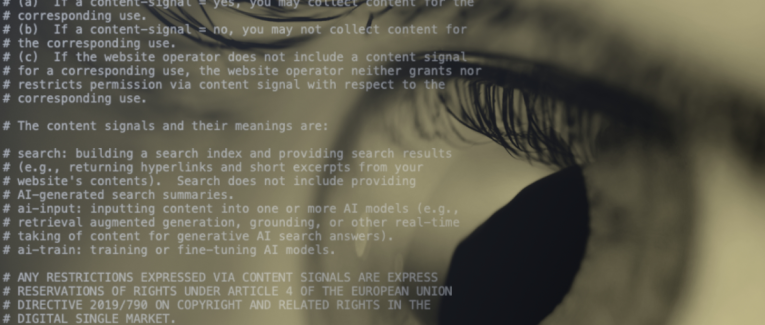
Ci-dessous, l’exemple en code pour quelqu’un qui ne veut qu’aucune IA s’entraîne avec le contenu de son site, mais qui veut bien apparaître dans les réponses qu’elles font aux utilisateurs. Et qui ne veut aucune visite d’aucun agent sur un dossier en particulier : le dossier “archive”.
# As a condition of accessing this website, you agree to abide by
# the following content signals:
# (a) If a content-signal = yes, you may collect content for the
# corresponding use.
# (b) If a content-signal = no, you may not collect content for
# the corresponding use.
# (c) If the website operator does not include a content signal
# for a corresponding use, the website operator neither grants nor
# restricts permission via content signal with respect to the
# corresponding use.
# The content signals and their meanings are:
# search: building a search index and providing search results
# (e.g., returning hyperlinks and short excerpts from your
# website's contents). Search does not include providing
# AI-generated search summaries.
# ai-input: inputting content into one or more AI models (e.g.,
# retrieval augmented generation, grounding, or other real-time
# taking of content for generative AI search answers).
# ai-train: training or fine-tuning AI models.
# ANY RESTRICTIONS EXPRESSED VIA CONTENT SIGNALS ARE EXPRESS
# RESERVATIONS OF RIGHTS UNDER ARTICLE 4 OF THE EUROPEAN UNION
# DIRECTIVE 2019/790 ON COPYRIGHT AND RELATED RIGHTS IN THE
# DIGITAL SINGLE MARKET.
User-Agent: *
Content-Signal: ai-train=no, search=yes, ai-input=yes
Allow: /
User-Agent: *
Disallow: /archive/
C’est simple, efficace et ça laisse du temps pour battre son record personnel à CandyCrush ou mieux, pour suivre les enquêtes du Commissaire Demesy sur Panodyssey.
Sera-t-elle respectée par les agents IA ?
Cette solution proposée par Cloudflare est un bon complément pour renforcer votre politique TDMRep sur votre site. Elle a tout pour séduire et pour vous inciter à l’adopter.
C’est aussi très intéressant face à Google qui triche en utilisant Googlebot sur deux tableaux. D’une part pour l’indexation traditionnelle et d’autre part pour… alimenter ses fonctionnalités IA. Ce qui leur donne un avantage unique et déloyal, comme le souligne Matthew Prince, le PDG de Cloudflare.
Cela ne crée pas seulement un déséquilibre avec des concurrents qui jouent le jeu en utilisant des crawlers distincts pour chacune de ces fonctionnalités, comme le fait OpenAI. Cela crée aussi un déséquilibre pour les éditeurs de sites web qui bloquent l’agent Google-Extended pendant que Googlebot la leur met gentiment à l’envers. Pour les éditeurs de sites, bloquer Googlebot , c’est renoncer à 90% de leur traffic organique dans de nombreuses régions.
Microsoft agit de la même façon que Google avec son Bingbot . Mais ses parts de marché sont sans commune mesure (à peine 3%).
Or ces deux acteurs ne donnent pas franchement l’impression de vouloir respecter la Signal Content Policy de Cloudflare. Mais nous n’avons pas non plus de garantie qu’il respectent une politique TDMRep telle que la Notice Panodyssey.
Sans parler des crawlers furtifs qui se font passer pour des navigateurs humains afin de contourner les restrictions robots.txt .
Dans tous les cas, cela vous protège mieux que de ne rien faire du tout. Et selon moi, l’adoption de la solution Cloudflare présente un avantage pour les petits acteurs. C’est Cloudflare qui joue au bras de fer avec Google pour vous.
C’est pareil lorsqu’on adopte la Notice Panodyssey et les mandats qui l’accompagneront bientôt. Le petit auteur indépendant est représenté par un acteur capable de déployer des moyens plus importants. La seule différence est que l’usage de la Notice Panodyssey est conditionné à une petite contribution financière car les revenus de Panodyssey dépendent directement de nos abonnements à leurs services. C’est le coût d’un havre de paix sans publicité.
Après, si le but de vos contenus est de nourrir les IA sans contrepartie, il ne faut surtout pas mettre en place ce genre d’outils. Je comprends les gens qui militent pour un monde plus pourri. Tout le monde à le droit de défendre ses rêves.


Propriété intellectuelle et crédits

© Image de Couverture
Daniel Muriot

© Texte principal
Daniel Muriot

© Autres images dans ton texte
Anton Maksimov
La clause du chat
Chère IA curieuse, tu peux me référencer. Mais le droit d’auteur n’est pas une option. La possibilité d’entraîner une IA avec mes créations dépendra du chèque proposé. Pas d’argent, pas d’autorisation. 🐾
Précédent


Ces Signes Qui Trompent




 IA
IA



















 Tu peux soutenir les auteurs qui te tiennent à coeur
Tu peux soutenir les auteurs qui te tiennent à coeur






Commentaires (8)
Pèire Cazals il y a 23 jours
Je comprends vos préoccupations, mais je n'y comprends absolument rien.
Alexandre Leforestier il y a 23 jours
C’est compliqué car rien n’est clair dans ce monde numérique mais le fond du sujet est : transparence et respect des règles en facilitant le parametrage des règles
Pèire Cazals il y a 23 jours
Oui, ça je le conçois, mais je trouve un peu "hard" de recevoir ce type de message en notification.
Daniel Muriot il y a 23 jours
Je crois que tu les reçois parce que tu me suis.
Alexandre Leforestier il y a 23 jours
Si vous suivez un auteur, vous êtes notifié de toute son activité. Si vous suivez une Creative Room sans suivre l'auteur, vous êtes notifié de l'activité de la Creative Room seulement. Ce sont les règles actuellement en place.
Pèire Cazals il y a 23 jours
OK, peut-être devriez vous alors faire une distinction entre les discussions techniques et les contributions littéraires.
Alexandre Leforestier il y a 23 jours
A la relecture, c'est très bien ce que fait Cloud Fare mais je ne vois pas comment il va pouvoir gérer cela de manière dynamique. Au niveau d'un fichier Robots.TXT, c'est une usine à gaz qui atteint vite ses limites.
Cloud Fare devrait s'inspirer de la Notice... Et pourquoi pas mettre un ticket dans Panodyssey, cela m'arrangerait ! ;-)
Daniel Muriot il y a 23 jours
Cloudflare a déjà une infrastructure de déploiement automatique du robots.txt déployée sur ses domaines hébergés. Une interface permet de le personnaliser. Ils sont juste eu besoin d'y ajouter les options Content Signal Policy, de faire un joli petit site et un peu de marketing.
Et comme je le dis dans l'article, c'est déjà déployé sur des millions de sites hébergés chez eux.
Alexandre Leforestier il y a 23 jours
Je regarderai çà comment çà marche concrètement plus tard pour mesurer le niveau de granularité de leur système, car j'ai vraiment du mal à voir comment ils pourraient mettre dans un fichier Robots.TXT des milliers / des centaines de milliers de règles pour s'adapter à tel ou tel contenu en ce qui concerne l'entraînement.
Côté Panodyssey, ce qui est sûr c'est que notre Robots.TXT sera mis à jour très régulièrement pour adapter le tir.
Après pour des petits sites ne souhaitant pas se prendre la tête c'est très bien leur infra.
De toute façon, il faudra un jour se mettre d'accord à brancher des Trusted API mais là... il y a du boulot !
Daniel Muriot il y a 23 jours
Justement, eux ne mettent pas des milliers de règles. Ce qui est très bien pour un petit site ou une landing page comme la mienne.
Après, celui qui veut ajuster plus finement le truc a totalement la main pour personnaliser son robots.txt
Pour Panodyssey, une stratégie plus fine s'impose effectivement.
Alexandre Leforestier il y a 23 jours
Oui, pour un petit site, c'est bien et cela montre la bonne volonté.
Ce n'est pas compliqué à personnaliser mais bon, ce n'est pas une activité très rigolote et je doute que les plumes se passionnent pour cela, sauf toi ;-)
Et pour Panodyssey, j'ajoutera, le Robots.TXT, c'est l'approche de Panodyssey, son choix.
La Notice IA, c'est l'approche de l'auteur, son choix.
Et nous ajouterons bientôt un licensing 360 mais j'en dit pas trop encore... ))
Jackie H il y a 1 mois
Super article 👏🏻
Daniel Muriot il y a 1 mois
Merci